Siamese Neural Networks for One-shot Image Recognition (2015)
https://www.semanticscholar.org/paper/Siamese-Neural-Networks-for-One-Shot-Image-Koch/f216444d4f2959b4520c61d20003fa30a199670a
[PDF] Siamese Neural Networks for One-Shot Image Recognition | Semantic Scholar
The process of learning good features for machine learning applications can be very computationally expensive and may prove difficult in cases where little data is available. A prototypical example of this is the one-shot learning setting, in which we must
www.semanticscholar.org
Research direction & Motivation
Main Purpose
Recognition with one image per class using Siamese CNN
Machine learning은 학습시 수많은 데이터를 필요로 하며 이에따라 학습비용의 소요가 매우 크다. 좋은 학습을 위해서는 robust한 feature를 학습하는 것이 중요한데, 이 과정에서 역시 데이터의 양적인 측면의 중요성은 불가피하다. 본 논문에서는 one-shot learning의 방법으로 이를 해결하고자했다. CNN이 고차원의 데이터 구조에서 중요한 feature들을 잘 잡아내는 것을 활용해 접목시켰으며 네트워크 구조는 Siamese 구조로, 완전히 대칭되는 구조를 가진 동일한 네트워크를 학습하는 방식을 제안했다.
물론 위와 같은 시도는 이전에도 활발했다. 2000년대 초반, target class에서 적은 양의 데이터가 주어졌을때 사전에 학습한 class들이 예측에 도움을 준다는 가정을 사용한 Bayesian framework에 대한 연구가 고안되었다. 그 가운데, 문자 인식 문제에서 Hierachical Baysian Program Learning, 일명 HBPL로 문자를 그릴 때 획정보를 사전정보로 활용하는 방식이 나타났다. 해당 방식은 이미지를 작은 단위의 조각들로 분해해 pixel들의 구조적인 설명을 이끌어내는 것이 목적이었다. 하지만 joint parameter space가 매우 넓어 적분의 측면에서 다루기가 힘들어 학습이 어렵다는 것이 단점이었다. 그외에도 음성인식에 있어서 Hierarchical hidden Markov model을 고안하는 등의 연구들이 존재했다.
Method
Flow & Architecture
전체적인 task는 크게 두가지로 나뉜다. 각각 verification task와 one-shot task이다. Verification task에서는 서로 같거나 다른 class를 가진 pair들을 이용해, 두 이미지가 서로 같은지 다른지를 판별하는 네트워크를 학습시킨다. 이때 사용하고자 고안한 네트워크는 Siamese Network로 서로 다른 input을 입력받아 상단의 energy function으로 합쳐진다.
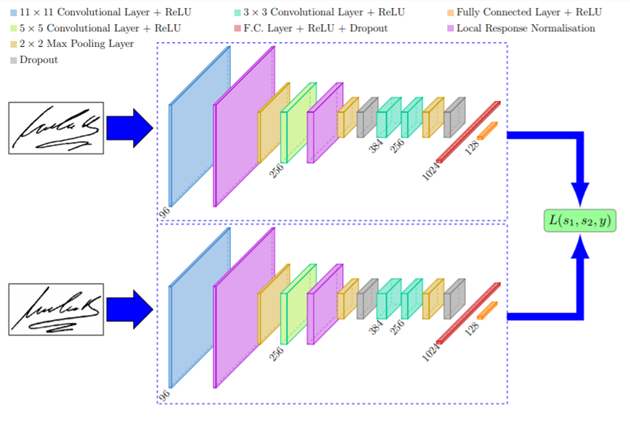
Siamese networks는 내부적으로 2개의 sub network가 존재하는데, 위 사진이 이를 잘 보여주는 예시이다(세부적인 layer 구조는 논문에서 제안하고 있는것과는 다르다). 두 네트워크의 구조가 동일하며 parameter까지 공유되기 때문에 완전히 동일한 symmetric한 네트워크라고 볼 수 있다. 따라서 동일한 이미지가 input으로 투입된다면 output 역시 같아야 하며, 다른 이미지더라도 sub1, sub2에 투입하는 순서와 상관없이 output pair는 동일해야한다.

모델은 다양한 크기의 CNN layer로 이루어지며 마지막에는 fully connected layer가 위치한다. 해당 fc layer에서는 4096개의 첫 번째 네트워크의 feature vector h1과, 두번째 네트워크의 feature vector h2사이의 L1 norm을 계산한다. 이는 투입된 서로다른 두 input간의 유사도를 측정하는 것과 같다. 최종적으로 sigmoid 활성화 함수를 통해 단일값을 산출하게되고, 1이면 같은 이미지 0이면 다른 이미지로 판별한다.
여기서 주목해야할 부분은 마지막 부분에서 두개의 sub model이 union되는 부분이다. 논문에서는 이를 'The units in the final convolutional layer are flattened into a single vector' 라고 표현하고있다. 각각의 feature가 flattened되고나서 아래와 같이 single vector들 간의 distance가 구해진다.

Experiments
실험에서는 One-shot task에서 자주 사용되는 Omniglot Dataset을 주로 사용했고, MNIST 셋도 추가적으로 사용했다. Omniglot은 40개의 알파벳과 10개의 알파벳으로 이루어진 background set과 evaluation set으로 구분되며, 전자를 verification 후자를 one-shot task 평가에 사용했다. Background set은 다시 train data와 validation data로 구성되고 evaluation set은 test data로 구성된다.
Verification

논문에서는 학습을 위해 총 30k, 90k, 150k 쌍의 데이터를 만든다. 이 쌍은 50%의 same image pair와 50%의 different image pair이다. 데이터 쌍을 만드는 순서는 아래와 같다.
- 40개의 backgroud set에서 30개를 train data로 10개는 validation data로 나눈다.
- 30개의 train set에서 20명의 사람이 쓴 이미지 중 12명의 이미지만 고른다.
- 즉, 30개의 alphabet에서 12명의 사람이 쓴 이미지만 추려와서 30k, 90k, 150k만큼의 이미지 쌍을 만든다.
- 여기서 8개의 transform을 이용하여 augmentation을 통해 이미지 데이터를 증폭한다. 총 270k, 810k, 1350k 개의 이미지 쌍이 생성된다.
이에 따라 150k training의 affine distortion case가 93.42의 가장 높은 verification accuracy를 달성했다.
One-shot learning
Verification task를 통해 siamese network를 최적화하게되면 이제 궁극적으로 새로운 test image에 대한 class prediction이 가능해진다. 따라서 One-shot learning task에서는 evaluation이 핵심인데, 이는 일반적인 머신러닝의 방법과는 사뭇 다르다. 일반적으로는 이미지 pair에 대해 같은지, 다른지를 맞추는 단순한 방식이었다면 논문에서는 n-way one shot task를 사용한다.
N-way one shot task는 한번에 n개의 class에 대해 판단하는 것이 핵심이다. 따라서 accuracy의 계산은 n개의 이미지 쌍에서 계산된다. 여기서는 20-way를 사용해 20개의 이미지 pair중 오직 한개의 이미지만 test image의 class와 같은 이미지이며 나머지는 다른 class의 이미지이다. 결국 evalution은 총 20 pair의 similarity 중 test image와 같은 class의 경우의 similarity가 가장 높아야 모델이 올바르게 예측한 것으로 간주했다.

실험은 10개의 알파벳에 대해 수행했으며 20-way이므로, 1 trial 당 200번의 one-shot learning을 수행하게된다. 또한 해당 실험에서는 repeated twice로 총 400번을 수행했다. 결과적으로 Convolutional Siamese Net은 매우 높은 수준의 수치를 기록했다. 비록 HBPL보다는 낮은 수치이지만, 사전정보를 기반으로 하는 HBPL과 달리 그 어떤 정보도 포함하지 않았다는 것을 고려하면 높은 수치라고 할 수 있다.
추가적으로 Omniglot에 학습된 모델이 다른 데이터셋에서도 보편화될 수 있는지를 알아보기 위해 동일한 네트워크를 MNIST에 대해서 10-way one-shot task를 수행했다. 그 결과 baseline으로 사용된 1-nearest neighbor가 26.5%인 것에 비해 70.3%를 기록했다. 이는 별도의 재학습 과정 없이도 네트워크가 similarity에대한 robust한 feature를 학습하여 타 데이터에도 적절하게 generalized된 것으로 보인다.



