InterpretML: A Unified Framework for Machine Learning Interpretability (2019.09.19)
https://arxiv.org/abs/1909.09223
InterpretML: A Unified Framework for Machine Learning Interpretability
InterpretML is an open-source Python package which exposes machine learning interpretability algorithms to practitioners and researchers. InterpretML exposes two types of interpretability - glassbox models, which are machine learning models designed for in
arxiv.org
Research direction & Motivation
Main Purpose
Constructing interpretable machine learning technique
ML의 다양한 분야에서의 발전되고 접근성이 높아짐에 따라, 사용자가 이해할 수 있는 설명 가능한 모델의 구축에 대한 수요가 증가했다. 특히 health care, finance, judicial 등의 분야에서는 단순한 성능보다는 결과에 대한 설명도 중요한 요소로 자리잡았다. 모델의 해석력은 model debugging, regulatory compliance의 ML 문제를 적용하는데 있어서도 중요한데, 이에 따라 통합된 API하에서 sota급의 성능을 보여주며 설명가능한 Interpret ML 이라는 pakage를 구축한 논문이다.
Pakage Design
배포된 pakage는 ML모델들에 대한 설명과 해석이 용이한 여러가지 모듈로 구성되어있다. 크게 두 부분으로 구성되는데, Glass Box와 Black Box로 나뉜다. 간략하게 설명하자면 다음과 같다.
Glass Box : 사용자에게 설명가능한, 명확한 모델들을 제공한다. 해당 모델들은 학습이 가능하며 pakage하에서 모두 높은 해석력을 제공한다는 장점을 가진다.
Black Box : 모든 ML의 pipeline하에서 설명 및 해석을 제공한다. SHAP와 LIME 등의 시각화를 기반으로 하는 기능들을 탑재하고있어, 변수들에 대한 중요도나 해석을 지원한다.
해당 pakage는 'explainable' 과 'convenience' 의 관점에서 다음과 같은 원칙에 따라 만들어졌고 소개하고있다.
1. Ease of comparision
모델들의 상호 비교가 용이하다. scikit-learn style의 API를 이용하여 알고리즘의 비교에 있어서 시각적 측면에서의 platform을 제공한다.
2. Stay true to the source
기존에 구축되어잇는 알고리즘과 시각화 기법을 최대한 이용해 가장 정확한 형태의 해석을 제시하고자 한다.
3. Play nice with others
호환성이 좋다. Jupyter Notebook, scikit-learn, plotly 등의 기본적인 툴들과 높은 호환성을 가진다.
4.Take what you want
사용자의 의도에 따라 쉽게 필요한 부분만 제어할 수 있다. 사용하고자 하는 기능만 간단하게 사용이 가능하다.
Expainable Boosting Machine
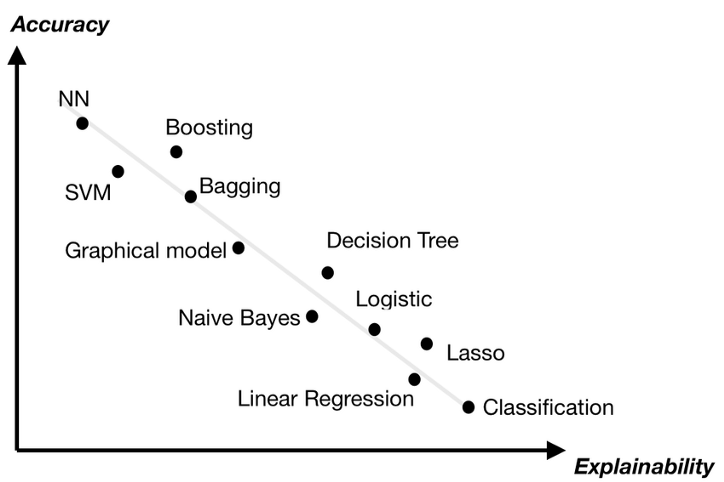
ML 분야에서 domain에 종속되지않고 다양한 분야에서 월등한 성능을 갖고있는 기법은 바로 Boosting 계열의 알고리즘들이다. 하지만 성능이 좋은 대신 치명적인 단점도 존재했는데, 간단한 변수의 중요도 정도를 제외하면 결과에 대한 설명이 불가능하다는 점이다. 일반적으로 높은 성능을 갖는 모델들은 설명가능성이 떨어지는 trade-off가 존재한다. 이러한 단점을 보완하고자 논문에선 Expainable Boosting Machine(EBM)을 제시했다.
Glass box에서 EBM이라는 모델을 제공하는데, 이 모델은 boosting을 기반으로한 알고리즘의 Randomforest, BosstedTree 등의 sota급의 성능을 보여주는 ML모델들 수준의 정확도를 가지는 동시에 해석력이 높으며 이해하기 쉬운 형태로 결과를 제공할 수 있다. EBM은 generalized additive model(GAM)에서 한 단계 더 발전된 형태로 이해할 수 있다.
< Why EBM is better? >

첫번째로 EBM은 bagging이나 gradient boosting과 같은 현대의 ML기법들을 이용해 feature function(fj)를 계산한다. 매우 낮은 learning rate로 round robin의 형태로 개별 feature에 대해 학습한다. 학습하는 과정에서 개별 feature들에 대한 최적의 feature function을 계산하고 예측에 있어서의 영향성을 시각화하여 제시한다.
다음으로 EBM은 자동적으로 feature들간의 pairwise interaction을 찾아내 정확도를 높인다. 식에서 보면 가장 우측에 있는 항에 해당하는 부분이다. 동시에 EBM은 속도 역시 우수하다. C++과 Python으로 작성되어 multi-core parallelization이 가능하다. EBM은 additive model로 fj가 각 feature 별로 예측에대한 기여성을 매우 쉽게 계산할 수 있으며 해당 term은 link function인 g를 통과함으로써 예측을 계산할 수 있다.

위 그림은 시각화된 결과에 대한 예시로, 좌측에서는 Age feature value가 20에서 50에서 증가함에 따라 중요성이 증가하고 있는 모습을 볼 수 있다. 우측에서는 많은 feature들 중 CapitalGain이 가장 높은 중요성을 가지는 feature로 나타났다.
< Experiments >
논문에서는 기초적인 데이터로 자주 사용되는 heart disease, breast cancer, telecom churn, adult income, credit fraud의 5개 데이터에 대해 LightGBM, Logistic Regression, RandomForest, XGBOOST와 성능을 비교했다. 모든 hyper-parameter는 default 값으로 적용되었으며, 최적의 정확도와 이해성을 위해서는 100 inner bags, 100 outer bags, 5000epochs, learning rate는 0.01을 적용하는 것이 좋다고 말하고 있다. AUROC를 metric으로 제시했다.
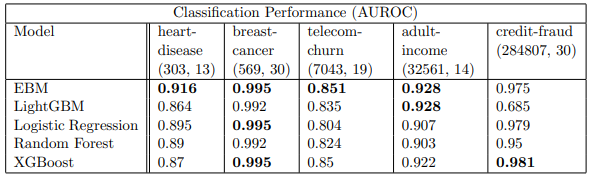

결론적으로 5개 중 4개에서 EBM은 XGBOOST, LightGBM과도 대등한 성능을 보여준다. 물론 위에서 언급한 개별 term을 additive한 형태로 갖고있어, training cost 측면에서 추가적인 소요가 불가피하지만 prediction시에는 사소한 addition만 추가되고 내부의 feature function을 참고하므로 오히려 매우 빠른 속도를 가진다는 장점이 있다. 제시된 plot을 보면 training time은 비교적 높은 위치에 위치해있으나, scoring time은 주로 낮은 위치에 있는 것을 확인할 수 있다.



