Unprocessing Images for Learned Raw Denoising (18.11.27) -
https://arxiv.org/abs/1811.11127
Unprocessing Images for Learned Raw Denoising
Machine learning techniques work best when the data used for training resembles the data used for evaluation. This holds true for learned single-image denoising algorithms, which are applied to real raw camera sensor readings but, due to practical constrai
arxiv.org
Research direction & Motivation
Main Purpose
Denoising through realistic image processing: Unprocess
Image denoising algorithm은 학습데이터를 얻는 것이 어려운 한계로인해 주로 인위적으로 생성된 인조 이미지를 이용해 학습한다. 이러한 인조 이미지로부터 실제 이미지로의 보편화는 카메라의 센서나, image를 processing하는 pipeline들에 대한 다양한 요소들을 고려해야하지만 간과되는 경우가 많아 이는 곧 성능의 저하로 이어진다는 문제점이있다.
Deep learning은 denoising에 있어서 효과적인 방법이 될수 있지만, 모델의 학습에 있어서는 많은 수의 paired dataset을 필요로한다. 따라서 일반적으로 인공적인 학습 데이터에 의존해 대부분의 학습이 이루어지므로 고전적인 algorithm들에 비해 부진한 모습을 종종 보이는 것으로 알려져있다.
본 논문에서는 이러한 문제를 실제와 거리가 먼 인공 학습데이터를 사용하기 때문이라고 가정하는데서 출발한다. 이전의 algorithm들은 noise가 additive, white, gaussian하다고 가정하는데 이는 실제와 부합하지 않는다. 이를 극복하기위해 image processing의 과정을 단계적으로 역변환하는 'unprocess'의 방안을 제시했다. 부가적으로 loss function을 평가할때는 processing에 관련된 요소들을 고려한 모델을 구성함으로써 denoising 후에 발생하는 광학적인 부분들을 학습시 고려하도록 했다.
Raw Image Pipeline
현대의 카메라는 noise의 다양한 변형을 통해 사진을 산출한다. 실제적인 인조 데이터의 생성을 위해 논문에서는 제안하는 pipeline에서 사진이 어떻게 변환하는 지를 설명하고있다.
Shot and Read Noise

Sensor noise는 shot noise와 read noise로 구성된다.
먼저 shot noise는 실제 빛의 강도를 의미하는 Poisson 분포를 의미하며, read noise는 0의 평균과 고정된 분산을 가진 gaussian 분포에 근사한다. 이를 통해 실제 signal인 x의 function을 이용해 관찰되는 y를 추정할 수 있다. 식에서 λread와 λshot은 셀서의 analog gain과 digital gain에 의해 결정된다. 이 두가지 gain level은 사용자 또는 자동화된 노출정도에 의한 ISO 빛의 광도 수준의 function으로, 카메라에 의해 설정된다. 따라서 인조 이미지를 생성하기위한 noise level의 선택을 위해, 실제 raw image 또는 해당 분포로부터의 shot/noise parameter들의 joint distribution을 모델링해 선정했다.
Darmstadt Noise dataset의 shot and read noise에 해당하며, noise parameter의 선정을 위해 붉은 선에 해당하는 distribution으로 부터 shot, read noise를 무작위 sampling을 통해 선정했다.
Demosaicing
일반적으로 카메라의 센서는 R-G-G-G와 같은 Bayer pattern안에서 배열된다. Darmstadt Noise dataset은 bilinear interpolation을 사용해 demosicing을 수행하는데, 해당 변환은 단순히 bayer pattern에 따라 3개의 color중 두가지 값을 제거하는 방식으로 이루어진다.
Digital gain
언급했듯이, digital gain은 보통 카메라의 자동화된 노출 algorithm에 의해 선택되기 때문에 이를 unprocessing하는 것은 어려운 일이다. 이를 변환시키기 위해서는 인조 데이터와 실제 데이터를 동시에 아우르는 marginal statistic에 부합하는 global scaling의 선정이 필요하다. 본 논문에서는 두 데이터 모두 exponential distribution에 의해 유도되는 것으로 가정하고, 해당 분포의 역함수를 이용한다. 이를 기반으로 scaling ratio를 정의하여 1.25를 선정했다. 따라서 1/1.25=0.8로 중심이 0.8, 표준편차가 0.1인 normal distribution으로부터 inverse gain을 추출해 사용한다.
White Balance
White balance 역시 image의 색상에 영향을 미치는 고려 요소 중 하나인데, 이 역시 자동화된 mechanism에 의해 결정되어 unprocessing이 어렵다. 그러나 Darmstadt Noise dataset은 wb에 대한 meta data를 갖고있으며 이러한 경험적인 분포로부터 실제에 가까운 데이터를 생성할 수 있다. 이때 red gain은 [1.9, 2.4], blue gain은 [1.5, 1.9]를 사용했다. 또한 highlight-preserving transformation 함수를 설정해 threshold t에 대해 일부는 선형적이고 일부는 cubic한 변환을 사용했다.
Color Correction
일반적으로 카메라 센서의 color filter는 sRGB 공간과 부합하지 않으므로, 카메라는 3x3 color correction matrix(CCM)을 적용해 RGB color space를 sRGB로 변환하는 과정을 거친다. Darmstadt Noise dataset은 총 4개의 카메라에서 찍힌 사진들로 구성되어있어, random한 sampling을 통해 선정된 CCM을 unprocessing함으로써 color correction의 효과를 상쇄시켰다.
Gamma Compression
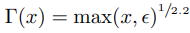
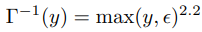
사람은 image의 어두운 부분의 gradation에 민감한 특징이 있다. 따라서 gamma compression은 낮은 강도의 pixel에 높은 표현력을 부여하기위한 방법으로 주로 사용된다. 여기서는 표준적인 gamma curve를 사용하며 이의 inverse function을 적용해 인조 데이터를 생성했다.
Tone Mapping
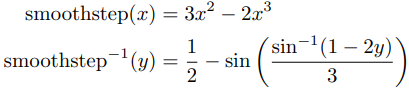
높은 표현력을 갖는 image는 극단적인 tone mapping을 필요로 하는 반면, 일반적인 낮은 수준의 표현력을 갖는 부분들도 image에 조화롭게 만들기 위해, S-shaped curve를 사용한다. 실제로 tone mapping을 완전히 모사하기는 어렵지만 간단한 'smooth step' curve로 구현된다고 가정하고 이의 inverse를 적용했다.
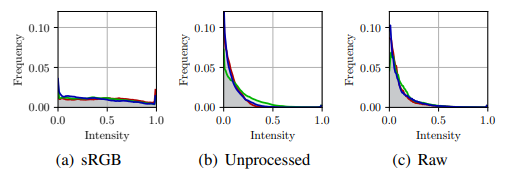
위와 같은 unprocessing을 거친 synthetic raw image는 제시된 histogram을 보면 실제 raw data와 상당히 유사한 분포를 가지는 것을 확인 할 수 있다.
Model and pipeline
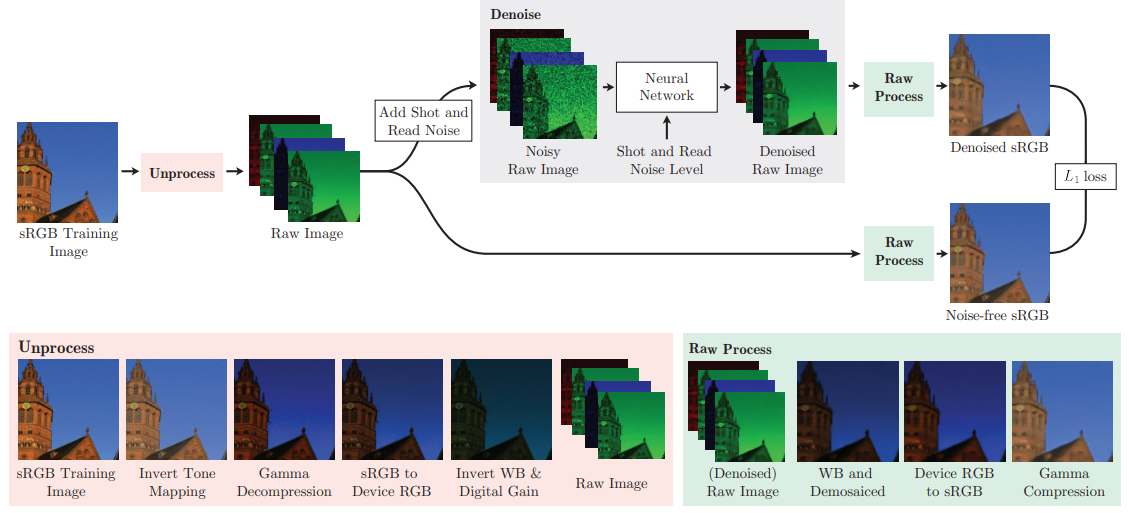
카메라는 raw image를 자체적으로 내장된 여러가지 광학적인 보정기능을 거친뒤, sRGB형태로 반환한다. 보통의 denoising 방법론에서 이렇게 카메라가 내놓은 ouput image를 통해 denosing을 실행할 경우, 보정된 여러 요소들로 인해 세밀한 denoising의 기능이 떨어진다. 따라서 본 논문에서는 sRGB image를 앞서 설명한 여러가지 'unprocessing'의 과정을 통해 raw image로 변환한다. 그 후, shot noise와 read noise를 추가해 noisy raw image를 만든다. 이를 noise lebel map과 함께 신경망에 통과시켜 denoised raw image를 형성하고 이를 다시 'processing'의 과정을 통해 카메라가 제공하는 기능들을 다시 입힌뒤, 출력된 sRGB형태의 image와 raw image에 곧바로 processing한 noise-free sRGB image(ground truth)와 비교해 L1 loss를 계산한다.
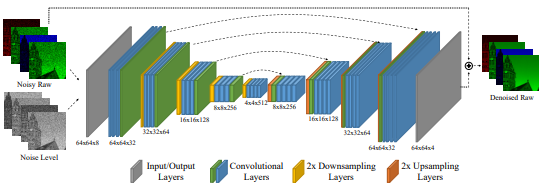
사용되는 모델은 U-net 기반의 구조에 encoder과 decoder간의 skip connection을 사용했다. Encoding시 box downsampling, decoding시에는 bilinear upsampling을 사용했다. Activation function은 PReLU가 사용되었다.
Experiments
Training
1,000,000 여장의 MIR Flikr dataset을 활용해 학습했으며, 각각 5%씩을 validation, test set으로 이용했다. 모든 image를 gaussian kernel로 down sample 시켜 각종 효과들을 줄였으며 random crop(128x128), horizontal and vertical flip으로 data augmentation을 적용했다. Opimizer는 Adam(1e-4, 0.9, 0.999, 1e-7)으로 16의 batch size로 학습했다.
Error를 sRGB로부터 계산한 모델과 raw로부터 계산한 모델 두가지를 사용했다. 둘의 차이는 loss를 계산할때 사용되는 output의 format의 차이에 기인한다. 즉, sRGB모델은 loss를 게산하기 전에 network의 output인 denoised raw를 processing을 통해 sRGB format으로 변환한다. 반대로 raw모델은 이러한 processing의 과정 없이 denoised raw를 곧바로 raw image와 loss를 측정하는 방식이다.
평가를 위해서는 noisy high ISO image와 noise-free low ISO ground truth image가 짝지어진 50개의 고해상도 사진을 가진 Darmstadt Noise dataset을 사용했다. 해당 dataset은 서로 다른 4개의 카메라에서 촬영된 실제 풍경을 담고있으며 각 카메라의 metadata와 noise porperty를 보존하고 있어 실험에 사용하기에 큰 장점이있다. 또한 저자들은 정답이 공개되지 않은 데이터를 활용한 online submission system을 구축하고 있어 평가에 적합하다고 판단했다.
Result
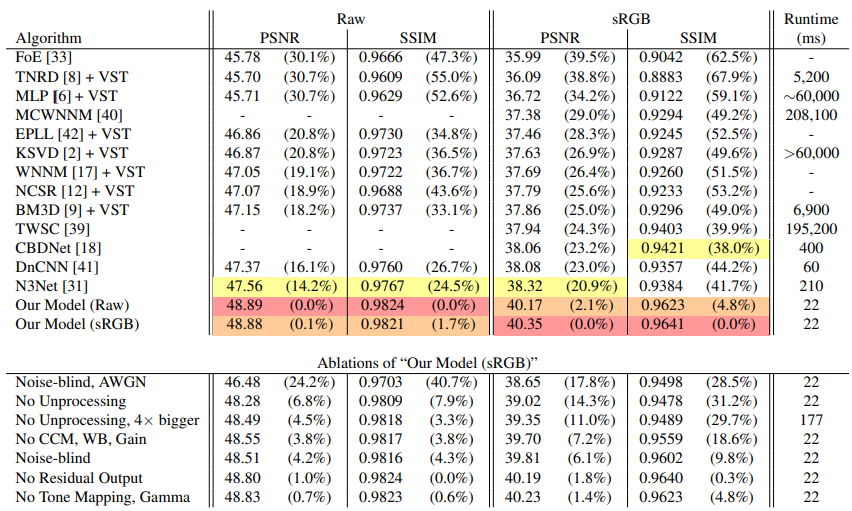
PNSR, SSIM metric을 통해 평가한 결과, 이전의 여러 algorithm과 비교했을 때 가장 높은 성능을 보여준다. 표에서 제시된 결과는 raw 또는 sRGB를 input으로 사용하여 나온 output에 대한 결과이다. 일부 모델들('-'로 결과가 표시)은 sRGB를 input으로 받을 시에 raw 형태로의 평가는 제한적이므로 결과가 생략되어있다. 또한 오류 감소율도 표기되었는데, 이는 PSNR을 RMSE로 SSIM을 DSSIM으로 변환한 상대적인 error 감소율을 의미한다.
추가적으로 논문에서 제시하는 방법이 효과적인지를 검증하기위해 unprocessing에 해당하는 기법들을 하나씩 제거하는 ablation study를 진행했다. 결과적으로 모든 기법들은 효과적이다. 특히 신경망에 noise level을 투입하지 않는 Noise-blind와 noise를 추가할 때 white gaussian noise를 사용하는 AWGN의 방법은 가장 큰 성능의 차이를 보인다. 따라서 논문에서 제시하는 unprocessing의 어느 과정이라도 제거하는 것은 성능의 하락으로 이어진다는 것을 의미하며 이는 sRGB모델에서 더 크게 나타났다.
Conclusion

저자들은 이전에 제시되었던 인조적인 이미지의 생성에 있어서 무분별한 가정을 통한 생성이 아닌, 광학적인 측면에서의 접근을 통해 denoising의 문제를 더 low-level task로 이끌어냈다. 카메라의 meta data를 활용해 간단한 신경망 구조에서도 효과적인 denoising 방법을 고안했으며 실제 image distribution에 근사한 인조 이미지를 생성해냈다. 이러한 unprocessing technique을 이용한 denoising은 이전 sota인 N3Net에 비해 성능이 크게 향상되으며, 동시에 runtime도 약 9배, CBDNet보다는 18배 빨라 제시한 baseline들보다도 효율적인 장점이있다.



