Better Fine-Tuning by Reducing Representational Collapse - (2020.08.06)
https://arxiv.org/abs/2008.03156
Better Fine-Tuning by Reducing Representational Collapse
Although widely adopted, existing approaches for fine-tuning pre-trained language models have been shown to be unstable across hyper-parameter settings, motivating recent work on trust region methods. In this paper, we present a simplified and efficient me
arxiv.org
Research direction & Motivation
Main Purpose
Overcome representational collapse when fine tuning by bounding divergence
Pre-trained된 모델을 기반으로 목적 task에 맞게 fine tuning을 수행할 경우, pre-trained된 모델의 general representation이 저하되는 현상을 'Representational collapse' 라고 한다. 이는 결과적으로 downstream task에서의 성능 저하로 이어지게된다. 본 논문에서는 fine tuning시에 나타나는 representational collapse를 극복하고자 trust region method에 기반을 둔 새로운 fine tuning strategy를 제안한다. 해당 방법은 general representation의 보존에 유리해 성능의 향상으로 이어지며, 기존에 고안된 다른 방법들(SMART, FreeLB)보다 연산이 단순해 속도가 빠른 이점이 있다.
Learning Robust Representations Through Regularized Fine-Tuning
Pretrained 모델을 특정 task에 맞게 fine-tuning 하면 representation의 generalizability가 훼손된다. 또한 그 상태로 다른 task에 대해 fine-tuning하면 pre-trained 모델을 fine-tuning할 때보다 성능이 낮아진다는 문제점이 존재한다. 따라서 pre-trained 모델의 변화량을 제한하고자하는 여러 시도가 있었다.
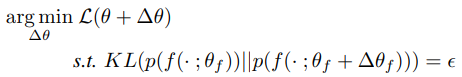
구체적으로, Parameter에 따른 일반적인 loss function의 최소화는 각 update step마다 표현분포의 공간에서의 움직임에 따라 제한된다. 이러한 제약된 최적화 문제는 representation에 직접적인 natural gradient descent를 수행하는 것과 같은데, 이 부분에 있어서 표현분포 p(f)에 대한 직접적인 접근은 제약이 따른다.

이전에는 대안으로 Bregmann divergences를 이용해 근사적 추정을 하고자 했다. 하지만 해당방법은 계산적으로 복잡하다. 그에 대한 대안으로 adversarial samples를 찾음으로써 근사적 추정이 가능했는데, 이것이 SMART에 해당한다. 이와 유사하게 FreeLB역시 adversarial loss를 직접적으로 최적화한다.

SMART는 부가적인 backward computation이 필요하여 연산량이 커지는 단점이 있어, 저자들은 다른 방법을 제시했다. SMART로부터 adversarial nature를 제거하는 대신 KLs의 smothness를 최적화했다. 또한 g(f(x))에서의 g에 최대 1-Lipschitz만큼 제한함으로써 추가적인 제약을 부가하여 더 효과적으로 f를 제한했으며 z로 표현되는 noise function은 noraml, uniform distribution을 사용했다. 언급한 추가적인 제약을 부여한 방법을 R4f, 그렇지 않은 경우를 R3f라고 칭한다. 해당 방법은 adversarial nature를 제거함으로써 연산적인 부하를 감소시키며, g를 smotohing함으로써 g(f(x))의 최적화를 더 용이하도록 만든다.
Experiments
실험은 크게 sentence prediction과 summarization task에 대해 기존에 제시된 fine tuning 방법들, 이를테면 SMART와 FreeLB와의 시간, 성능 측면에서의 비교에 초점을 맞췄다.
Sentence Prediction
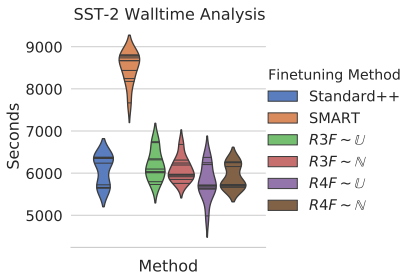


해당 task에서는 GLUE dataset에 대해 RoBERTa 모델을 fine-tuning했다. 10번의 random seed를 통해 시간및 성능의 분포를 비교했다. SMART 방법돠 제안한 방법은 월등히 짧은 walltime을 가지며 성능의 median, max 값 모두 높은 모습을 보여준다. 마찬가지로 아래와같이 XNLI task에서도 sota에 준하는 성능을 보여준다.

Summarization

다음으로 summarization task에서는 sota를 달성했다. CNN/Dailymail, Gigaword, RedditTIFU를 사용했다. 해당 task는 generation task로 classification head에 해당하는 g function이 없어 R4f는 적용이 불가능하며 R3f에 label smoothing loss를 적용했다. 그 결과, 기존의 PEGASUS나 ProphetNet을 큰 차이로 능가하는 새로운 sota를 달성했다.
Probing Experiments
논문에서 정의하고 있는 representational collapse는 task와 무관하게 fine tuning시에 나타나는 기존의 학습된 표현들의 표현력 저하를 의미한다. 이를 최소화하고자 논문에서는 새로운 strategy를 적용해 성능의 개선으로 이끌었다. 하지만 실제 representational collapse의 개선여부에 대해서 측정하는 것은 어려운 일이다. 따라서 여기서는 해당 개념의 존재 및 개선여부를 보여주는 것에 초점을 맞추어 다양한 실험들을 제시했다.
Probing Generalization Of Fine-tuned Representation

여기서는 다양한 fine tuning strategy의 보편성을 보기위해 다음과 같은 방법을 사용했다.
우선 특정 task에 대해 모델을 1차적으로 학습시킨뒤 가중치를 동결시켰다. 다음으로 모델의 최종 linear top layer에만 다른 task에 대해 fine tuning하여 성능을 측정하는 방법을 취했다. 실험에서는 SST-2에 대해 학습한 RoBERTa 모델을 6개의 GLUE task에 적용했다. 그 결과, 대부분의 task에서 SMART나 Standard보다 더 우수한 성능을 보여주었다.
Probing Representation Degradation
학습이 이루어짐에 따라 발생하는 representational collapse의 양상을 보기위한 실험으로, 다양한 dataset에 대해 순차적으로 fine tuning하며 나타나는 성능의 저하를 보여준다.

SST-2, QNLI, QQP, RTE 순으로 학습함에 따라 accuracy의 변화가 나타나는 것을 볼 수 있는데, R4f를 적용한 경우가 일반적인 경우보다 그 저하 폭이 훨씬 작은 것으로보아 representation을 더 잘 보존하고있음을 나타낸다.
Probing Representation Retention
이전 실험에서는 representation collapse에 따른 degradataion에 초점을 두었다면, 여기서는 보존에 초점을 둔다. 다른 task를 거친뒤, 다시 동일한 task를 만났을 때의 성능을 평가하고자한다. 이를 위해 여러 dataset을 거치는 일련의 cycle을 만든다.

예를들면, A와 B와 C가 있을때 A->B->C 순으로 학습한 뒤 다시 A의 성능을 측정한다. 이것이 첫번째 cycle이 되며, 실험에서는 4개의 dataset에 대해 각각 3번의 cycle에 따른 성능을 제시했다. 다른 실험과 마찬가지로 R4F의 방법이 representation을 더 잘 보존하고있어 cycle이 거듭될 수록 R4F의 성능 향상 폭이 크게 나타나는 것으로 볼 수 있다.
Conclusion
Fine tuning을 다양한 분야에서 널리 사용되고있다. 특히 NLP에 있어서 다양한 주제의 글 또는 기사 등의 contents에 대해 pre-trained 모델들이 많이 출시되고 있으며 이를 바탕으로 fine tuning하는 방법이 하나의 경험적인 규칙으로 자리잡았다. 하지만 해당 과정에서 발생하는 기존 학습정보의 손실로 인해 특정 목적에 맞는 task에 대한 성능이 저하되는 현상이 발생하는 것을 저자들은 representational collapse 라고 정의해 이를 완화하고자 했다. 그 과정에서 제시되었던 SMART, FreeLB등이 존재했지만, 비용적인 측면의 문제점을 인식하고 새로운 규제 방법인 R3F, R4F의 방법을 제시했다. 결론적으로 representation의 효율적인 보존을 통해 general한 성능의 저하를 완화함으로써 일부 task, summarization에서는 새로운 sota를 달성했다.



