(1) 에서는 CNN모델을 직접 구성해 고양이와 강아지 사진을 분류하는 분류기를 구축했다. 모델 구축에 앞서 Image Augumentation을 통해 데이터를 변형해 수를 증강시켰고 약간의 전처리가 포함되었다. 이는 이미지 작업에있어서 가장 기초적인 작업이며 결론적으로 Validation Set에 대해 0.78정도의 정확도를 달성했다.
이번에는 모델을 처음부터 학습시키는 것이 아니라 기존에 대량의 데이터셋으로부터 학습된 좋은 가중치를 통해 새로운 이미지를 학습하는 Transfer Learning을 접목시킨다. 전이학습은 이미지 분류에 있어서 성능을 크게 끌어올릴 수 있어 자주 사용되는 기법중 하나이며 상당히 다양한 전이학습 모델들이 존재한다. 이 중 사용할 모델은 VGG16으로 ILSVRC의 대회에 맞게 제작되어 1000개의 Class를 분류하는 모델이다. Keras에 내장되어 있어 편리하게 사전에 학습된 가중치를 불러와 바로 사용이 가능하다.
Transfer Learning

전이학습에는 크게 3가지 방법이 있다.
첫번째는 Full-Training이다. 모델의 구조만 가져와 가중치를 초기화 한뒤 학습시키고자 하는 데이터 셋을 직접 훈련시키는 방식이다. 주로 데이터의 양이 충분하고 컴퓨팅 파워가 좋은 편일때 사용하며 이 경우 기존에 다른 데이터셋으로부터 학습된 좋은 가중치들은 사용하지 못하며 구축된 모델의 형태만 사용하는 것과 같다.
두번째는 Fine-Tuning이다. 기존에 학습되어져 있는 모델을 기반으로 새로운 목적에 맞게 변형하고 기학습된 가중치로 부터 학습을 업데이트 하는 방식을 말한다. 또한, 모델의 파라미터를 미세하게 조정하는 행위를 말한다. 일부 Layer는 가중치를 고정시키고 다른 일부 Layer는 데이터 셋을 학습시켜서 얻는 새로운 가중치를 적용하게된다. 이 경우 분석가는 어느 층까지 가중치를 동결시킬지를 결정해야한다.
세번째는 Feature Extraction 방법이다. 학습된 모델의 최상위층만 현재 데이터 분석의 목적에 맞게 수정하고 그외에 Convolution Layer에 해당하는 층의 가중치는 동결시킨다. 일반적으로 데이터를 해당 모델로 예측하여 생성된 Bottleneck Feature만 뽑아내고, 이를 이용하여 최상위층에 새롭게 연결된 Fully-Connected Layer를 학습시켜 사용하게 된다.
< VGG16 >
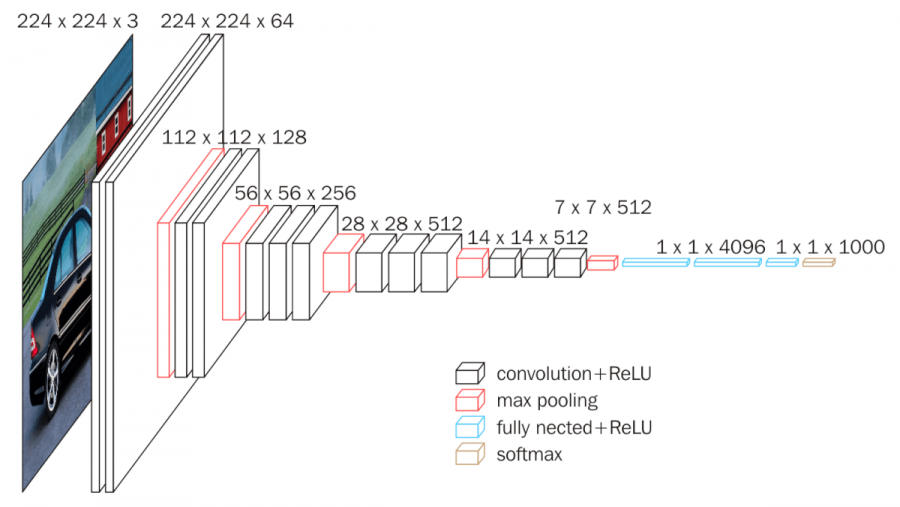
분석에 앞서 사용할 모델은 VGG16으로 ILSVRC의 대회에 맞게 제작되어 1000개의 Class를 분류하는 모델이다. Keras에 내장되어 있어 편리하게 사전에 학습된 가중치를 불러와 바로 사용이 가능하다. 해당 모델은 ImageNet Challenge에서 Top-5 테스트 정확도를 92.7% 달성하면서 상당한 관심을 불러일으켰다. 2012년에 발표된 AlexNet과 비교해 볼때 8-layers를 사용한 Alexnet 모델보다 깊이가 2배 이상 깊은 네트워크의 학습에 성공했으며, 이를 통해 대회에서 오차율을 절반으로 줄이는 성과를 보여주었다.
VGG16은 총 13개의 Convolution Layers와 3개의 Fully-connected Layers로 구성되어 있다. 각 Convolution층은 3x3의 filter size를 가지며 stride는 1을 사용했다. 또한 각 Convolution Layer 다음에는 2x2 형태의 Max Pooling 층이 위치하고 있으며 Activation Function은 ReLU를 사용했다. 여기서 VGG16은 3x3의 고정된 filter size를 사용했는데 이는 다음과 같은 장점을 가진다. 필터를 거칠 수록 이미지의 크기는 줄어들게되는데, 필터의 사이즈가 클 수록 이미지가 줄어드는 것이 빨라지고 레이어를 깊게 만들기 어려워진다. 그렇기 때문에 필터를 가장 작은 사이즈인 3*3으로 설정해 다수의 레이어를 거치더라도 상대적으로 레이어가 깊은 모델을 만들 수 있게 하였다. 동시에 연산시 발생하는 parameter의 수가 줄어드는 효과와 ReLU가 활성화 함수로 들어갈 수 있는 곳이 많아진다는 장점이 있다.
4. Feature Extraction
from tensorflow.keras.applications import VGG16
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))# Modeling
model = Sequential()
model.add(conv_base)
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
print('가중치를 동결하기 전 훈련되는 가중치의 수:', len(model.trainable_weights))
conv_base.trainable = False
print('가중치를 동결한 후 훈련되는 가중치의 수:', len(model.trainable_weights))
가중치는 'imagenet' 에서 얻은 가중치를 사용하며 최상위 층은 현재 분석목적에 맞는 Fully-Connected Layer를 적용할 것이므로 제거한 모델을 불러온다. 다음으로 언급한 Fully-Connected Layer를 추가해 전체 모델을 구성한다. trainable옵션을 통해 VGG16모델이 학습시 가중치가 초기화되지 않도록 가중치를 동결한다.
최종적으로 이후 추가한 Dense Layer만 가중치가 학습된다.
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['acc'])마찬가지로 Image Augumentation을 적용하고 모델을 compile하면 학습을 위한 세팅이 종료된다.
history = model.fit(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50,
verbose=2)
. . .

특성 추출기로 사용한 전이학습의 방법은 최종적으로 0.9의 Validation 정확도를 얻었다. 이전의 처음부터 가중치를 학습시키는 방법인 Basic 모델의 정확돠 약 0.78정도였던 것에 비하면 상당히 높은 폭의 성능향상을 보여준다.
5. Fine Tuning
# Modeling
model = Sequential()
model.add(conv_base)
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(1, activation='sigmoid'))conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
print('훈련되는 가중치의 수:',
len(model.trainable_weights))
block5_conv1이라는 layer부터 가중치 동결을 해제한다. 그렇게되면 총 3개의 layer의 가중치를 학습시에 학습하며 튜닝하게되며 그외의 가중치는 동결된다. 총 10개의 가중치가 훈련된다.
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
history = model.fit(train_generator, steps_per_epoch=100, epochs=30,
validation_data=validation_generator, validation_steps=50)
. . .

# Test set evaluation
test_generator = test_datagen.flow_from_directory(test_dir, target_size=(150, 150),
batch_size=20, class_mode='binary')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test acc:', test_acc)
동일하게 30 epochs를 학습시켰다. Validation셋 정확도는 0.93정도를 기록했으며 앞선 모델들보다도 더 좋은 성능을 기록했다. 마지막으로 별도의 Test셋을 통해 Evaluation을 진행했다. 실제 성능의 비교는 독립적인 Test셋으로 이루어져야한다. 여기서는 0.934로, 지금까지 나온 수치중 가장 높은 수치를 기록한다.
정리하자면 앞서 사용된 세가지 모델은 모두 동일한 image augumentation을 사용했다. 결과적으로는 Basic CNN < Feature Extractor < Fine Tuning 순으로 높은 정확도를 보였으며 Transfer Learning이 적용된 두 모델은 Basic모델보다 현격한 성능의 개선을 이뤄냈다.
이렇게 전이학습은 처음부터 가중치를 학습시키는 것보다 비교적 높은 성능향상을 가져온다. 데이터가 적은 경우 이 방법은 매우 효율적일 수 있으며, 심지어 많은 경우에도 이미지 데이터 분석에있어서는 빈번하게 사용된다. 여기서는 널리 쓰이고 유명한 'Cats and Dogs' 데이터셋을 사용했지만 다양한 분야의 데이터에 쉽게 접목될 수 있으며 이를 통한 예측정확도의 향상을 유의미해보인다.
다음에서는 학습된 모델을 바탕으로 Conv Net을 시각화하여 각 layer가 데이터의 어떤 특징, edge들을 파악하고 학습하고 있는지를 파악한다. 특성지도를 추출하여 Layer를 통과할 때마다 이미지가 어떻게 변화하는지 확인하고 CNN이 어떤식으로 해당 이미지들을 학습하는지를 시각화하고자한다. 또한 새로운 이미지에 대해 이미지의 어떤 부분이 해당 이미지를 특정 카테고리로 분류시켰는지에 대한 특성지도도 확인해 예측결정요인을 이해할 수 있다.
'Deep Learning > Vision' 카테고리의 다른 글
| AutoEncoder (0) | 2021.06.21 |
|---|---|
| Image Classification < Basic To Transfer > - (3) (0) | 2021.04.05 |
| Image Classification < Basic To Transfer > - (1) (0) | 2021.03.27 |


